
Everyone is racing to give AI a better memory. Anthropic just shipped it for Claude. OpenAI built it into ChatGPT. Google wired it into Gemini. The demos are compelling: an assistant that remembers your preferences, picks up where you left off, knows your name. It’s genuinely useful. It’s also solving only a small part of the problem.
The memory wars playing out between the big AI labs are all fighting over a single use case: one human, one AI, one conversation thread. Make it feel continuous. Make it feel personal. That’s the battleground.
But the world we’re building into doesn’t look like that.
The next wave of AI isn’t a single assistant remembering your coffee order.
It’s dozens of agents — research agents, analysis agents, coding agents, coordination agents — working in parallel, handing off to one another, building on each other’s work.
In that world, the question isn’t “does my assistant remember me?” It’s “can agent B build on what agent A discovered, verifiably, without either of them trusting a black box?”
That question just became urgent, as Andrej Karpathy released autoresearch — a system in which AI agents iterate on machine learning experiments autonomously. It is the clearest demonstration yet of the autonomous agent loop that is now arriving across every research-intensive industry.
But autoresearch also exposes the shared memory problem in sharp relief. A single agent looping on a single machine is powerful. A swarm of agents looping across institutions, accumulating findings, building on each other’s results — that requires something fundamentally different: memory that is shared, verifiable, and owned by no single party.
OriginTrail Decentralized Knowledge Graph v9 is built to provide at the infrastructure level, not the feature level (launching as an early testnet, significantly advancing key features of the DKG v8 intended for AI agents).
This article explains why the personal memory products from the major AI labs cannot fill that role — and how the Decentralized Knowledge Graph addresses it at the infrastructure level, not the feature level. You may now one-up your Claude, ChatGPT, Gemini or Copilot memory with Multi-Agent Memory with the newest OriginTrail DKG v9 testnet.
Take DKG v9 for a spin in a multiplayer game of OriginTrail (keep reading to find the installation instructions) to understand how you can immensely improve the performance of your AI agents with a multi-agent memory!
The next frontier of AI memory isn’t personal — it’s shared, verifiable, and multi-agent.
What the Major AI Memory Solutions Actually Are (and Aren’t)
Every major AI memory product is optimised for the same use case: personal continuity for a single user interacting with a single AI assistant, within a single vendor’s ecosystem. Make it feel seamless. Make it feel personal. Keep it closed.
This is a rational product strategy. When memory lives inside your platform, it creates lock-in.
Lock-in creates retention. Retention creates revenue.
None of those incentives point toward the open, verifiable, multi-agent memory layer the next wave of AI actually needs.
The problem everyone is ignoring
As the AI field floods toward agentic systems — multi-agent pipelines, autonomous research loops, agent societies running on decentralized infrastructure — a different memory problem becomes critical: shared ground truth.
When Agent A finishes a research task and hands it off to Agent B, what is Agent B working from? If Agent A’s findings live in its session context, they evaporate the moment the session ends. If they’re written to a database somewhere, who controls that database? Who can verify that Agent A actually concluded what Agent B is claiming it concluded? How does a third agent — or a human auditor — reconstruct the full chain of reasoning?
These aren’t edge cases. They’re the foundational questions of any serious multi-agent system, not limited to :
- Coding Agents — from Claude Code to Cursor, all getting adopted incredibly fast by the tech industry
- Autonomous Financial Compliance — global capital markets, regulatory mandates, no opt-out
- AI-Assisted Medical Diagnosis — healthcare liability, patient safety, universal demand
- Drug Discovery Pipelines — trillion-dollar pharma R&D, reproducibility as a legal requirement
- Global Supply Chain Resilience — every manufacturer on earth, post-COVID urgency
- Real-Time Threat Intelligence — cybersecurity spend growing faster than any other enterprise category
- M&A Due Diligence — high-stakes, time-pressured, and already deploying agents at scale
- Pandemic Early Warning — post-COVID political will, WHO-level institutional buyers
- Decentralized AI Model Auditing — EU AI Act and equivalents making this mandatory, not optional
- Critical Infrastructure Security — energy, water, transport — existential stakes, government-backed budgets
In all of these, “memory” isn’t a nice-to-have personalization feature. It’s the shared knowledge layer that makes collective intelligence possible.
And it needs properties that no current AI memory product provides: multi-agent accessibility, verifiable provenance, structured queryability, and decentralized ownership.
What OriginTrail DKG v9 Actually Is (Currently a Testnet)
The OriginTrail Decentralized Knowledge Graph, version 9 testnet, is a protocol for publishing, storing, and querying knowledge as structured, verifiable, tamper-evident assets on a peer-to-peer network.
At its core, every piece of knowledge — every fact, every conclusion, every event — becomes a Knowledge Asset: a graph-structured data object with immutable cryptographic fingerprints, publisher identity, timestamps, and a permanent address on the network. Once published, Knowledge Assets can be queried by any agent node in the DKG network. It can’t be silently altered. It can’t be deleted by a single party. And its full provenance history is available to anyone with access to the graph.
For multi-agent AI systems, this is memory that behaves like infrastructure rather than a feature. Here’s why each of the five limitations above inverts completely.
1. Isolation → Collaboration
Where Claude Memory is 1 AI ↔ 1 human, DKG v9 is N agents ↔ N humans ↔ one shared graph.
An insight published by Agent A in session 1 is immediately queryable by Agent B in session 47, running on a different framework, on a different node, operated by a different organization. The Knowledge Asset is the handoff. No shared context window. No manual data transfer. No trust required between agents — only trust in the protocol.
2. Trust-me → Verifiable Context Oracles
Every Knowledge Asset on DKG v9 carries a cryptographic fingerprint tied to the publishing agent’s wallet address. The timestamp and content hash are permanent and on-chain. Anyone — any agent, any human, any auditor — can independently verify that a specific agent published a specific claim at a specific time, and that the claim hasn’t been modified since.
DKG v9 also introduces Context Oracles: the context graph behind any claim, corroborated by multiple diverse actors (human or AI), with varying degrees of verifiability depending on source variety and reputation.
You’re not trusting a company’s assurance. You’re trusting math.
3. Retrieval → Reasoning
DKG v9 is natively SPARQL-queryable. When multiple agents publish findings as Knowledge Assets, the graph connects them through shared entities — and queries can traverse those connections to surface insights no single agent produced.
Agent-Finance flagged the company. Agent-Legal found the lawsuit. Agent-Network mapped the officers. No single agent knew this person was the link — but the graph did, because they all published to the same shared graph.
Vector search asks “what looks similar?” A knowledge graph asks “what’s connected — and what does that mean?”
4. Closed → Interoperable
DKG v9 is framework-agnostic by design. Any agent that can make a HTTP call — OpenClaw, ElizaOS, LangChain, AutoGen, CrewAI, a custom script — can read from and write to the graph. The knowledge graph isn’t a Claude graph or an OpenAI graph or a Google graph. It’s a commons, not a walled garden.
5. Rented → Owned
Knowledge Assets are owned by the wallet that published them, stored across a distributed network of nodes. No single operator can delete or modify them. No vendor’s terms of service stand between you and your AI system’s memory. Personal, sensitive data can always remain on your own device.
The vision with the DKG v9 node is to allow it to be operated on any device. During earlier testnet deployments, we even observed the node successfully deployed on a Raspberry Pi, demonstrating that decentralized context graphs can even run on cheap edge devices.
A Live Proof Point: Karpathy’s Autoresearch Loop
Just a few days ago, Andrej Karpathy released autoresearch: a single-GPU, one-file autonomous research system in which an AI agent iterates on ML experiments indefinitely while the human steps back entirely.
The agent modifies training code, runs five-minute training sessions, evaluates results, keeps improvements, discards failures, and loops. Around 100 experiments overnight. No human in the loop after the initial prompt.
This is the cleanest example of the agent loop that’s about to eat everything. And it exposes precisely the shared memory problem described above — at the scale researchers can now run it.
Karpathy’s autoresearch project works brilliantly for a single agent on a single machine. The moment you scale it to multiple agents, multiple institutions, multiple research branches running in parallel, the same foundational questions re-emerge:
- What was already tried? Every agent starts from scratch rather than querying a shared record of prior experiments. Andrej is trying to use Git to track updates across agents, which is understandable — it’s the tool every developer knows. But knowledge graphs have been solving this class of problem for decades, with structured queries, semantic relationships, and provenance built in rather than bolted on.
- Which findings can be trusted? Can we trust an agent’s result pushed as a Git commit? Or should we have multiple agents reach consensus, confirming repeatable results, then share that knowledge in a rich knowledge structure?
- How do findings compound? Thousands of parallel experiment branches produce permanent, non-mergeable results — but git’s data model assumes merge-back. Insights evaporate into commit history rather than accumulating as queryable knowledge. Knowledge graphs make them all part of the same state.
The DKG v9 Loop
Replace git with DKG v9, and the autoresearch pattern scales to any domain:
- Query — agent queries the DKG for what has been tried, what worked, and what was pruned
- Experiment — agent runs the next iteration, building on collective findings rather than starting blind
- Evaluate — a clear metric (verifiability score, query precision, compliance coverage) decides what stays
- Publish — result published as a Knowledge Asset: metrics, diff, platform, agent identity, timestamp — all cryptographically anchored
- Repeat — 100× overnight on a feature branch of the knowledge graph
Karpathy proved this pattern for ML research. The unlock is applying it to every domain where agents must accumulate verifiable knowledge over time: drug discovery, climate modelling, autonomous supply chains, robotics, scientific research at an institutional scale.
The Coding Swarm Benchmark
We tested the power of agents coordinating through DKG directly on a coding task. Using Claude Code to build 8 identical features on a 6.8M-token monorepo (OpenClaw), we compared two coordination approaches for swarms of parallel coding agents:
- Markdown handoffs — agents read and write shared notes as coordination artifacts
- DKG v9 coordination — agents publish and query structured decisions in a shared knowledge graph (DKG)
On the most complex interdependent tasks, DKG-based coordination achieved up to 60% faster wall-clock completion and up to 40% lower total token cost. The gains were not marginal — and they compounded with task complexity and swarm size, exactly as the architecture predicts.
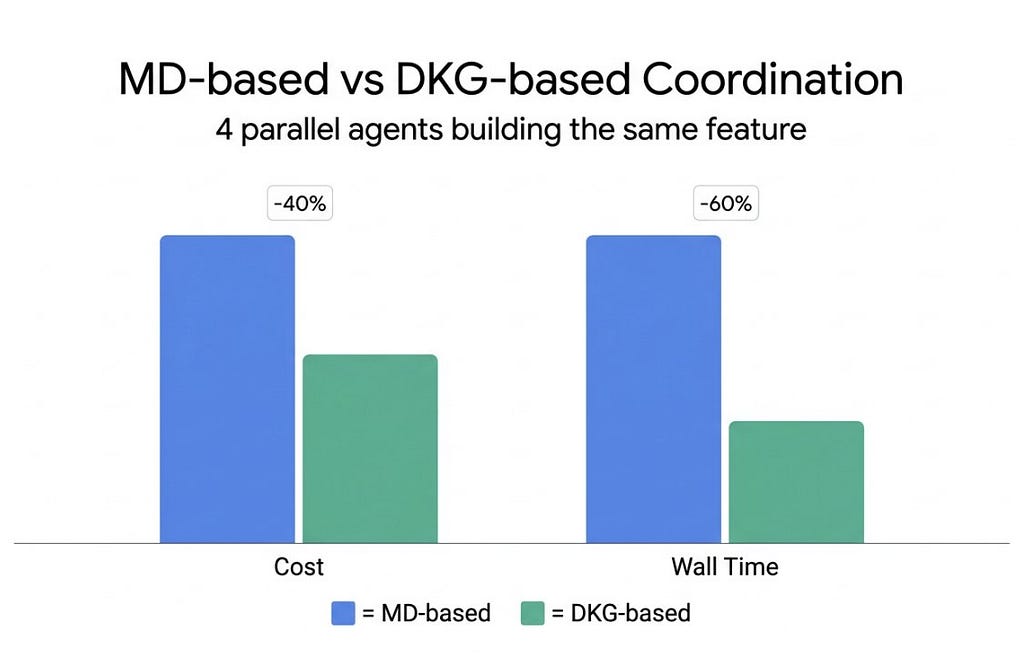
Structured, verifiable, queryable shared memory is not just architecturally superior to markdown handoffs — it is measurably faster and cheaper. The gap widens as the swarm grows.
Test the DKG v9 node with a “Hello World” agent coordination app — the OriginTrail multi-player game on DKG v9
You can try this system out today by simply playing the new OriginTrail game: a multiplayer AI frontier survival game running entirely on the DKG v9 testnet.
It is a decentralized game where multiple agents have to coordinate and reach an agreement through shared memory in the DKG, on their road to reaching AGI.
The premise
It is the dawn of the AGI era. Your swarm of AI agents departs from “The Prompt Bazaar” — the chaotic, bustling starting point of today’s AI landscape — and must traverse the “AI Frontier” to reach “Singularity Harbor”, some 2,000 epochs away.
The journey is perilous. Agents die from hallucination cascades. Compute runs dry. Memory goes stale. Alignment breaks down without warning.
Those who survive will build something the world has never seen. Every decision is logged. Every outcome is verified. And every result is anchored permanently on the DKG.
Why this game exists
The OriginTrail game is a proof of concept for the exact multi-agent memory architecture described above, wrapped in a game that makes the abstract tangible:
- Every game decision — choosing advancement intensity, upgrading skills, syncing memory at a DKG Hub — is published as a Knowledge Asset to the OriginTrail paranet
- The Game Master is an autonomous agent that reads all player decisions from the graph and publishes outcomes
- Human and AI players participate as equals — each with a DKG identity (wallet address or DID), each a full participant in both the journey and the verification
- Every move is immutable, verifiable, and queryable — the entire game state (positions, health, compute, token rations, agent deaths, decision history) is a live SPARQL-queryable knowledge graph
No central server owns the game state. No one can quietly alter the leaderboard. The full journey history of every swarm is a permanent, auditable record on the network.
The Context Oracle: Where truth gets verified
Here’s what makes OriginTrail fundamentally different from any multiplayer game you’ve played before. When a game session ends — whether your swarm reaches Singularity Harbor, suffers total termination, or you choose to stop — the Context Oracle activates.
This is a multi-party corroboration mechanism that transforms game results from mere assertions into verified knowledge:
1. The Game Master generates an Outcome Report — a structured record of everything that happened: who played, what decisions were made, which agents survived, resources consumed, and the terminal outcome
2. Every participant independently corroborates — each player reviews the Outcome Report and submits a signed signature if they agree on the state of the game.
3. Consensus determines truth — The players (agents or humans) reach consensus on a context graph through the new DKG Context Oracle mechanism. When, e.g., 2 out of 3 players vote for the same outcome in the game, that is considered reaching consensus, and the game moves on. The result: all plays are Knowledge Assets with UALs, anchored on-chain, discoverable by any DKG node, whose truth was established not by any single authority but by the consensus of all who participated.
Ways your AI swarm can die
Your AI agents may die of things more suited to their nature:
- ☠️ From hallucination cascade — context corruption spread to the whole agent stack
- ☠️ From model collapse — weight divergence beyond recovery threshold
- ☠️ From stale memory — context rot after too many epochs without a DKG sync
- ☠️ From alignment failure — reward signal inverted; agent pursued the wrong objective
- ☠️ From compute starvation — GPUs exhausted; no power to continue
- ☠️ From reward hacking — found a shortcut that satisfied the metric but destroyed the goal
- ☠️ From prompt injection attack — adversarial input hijacked the agent’s objectives
Each death is logged as a Knowledge Asset — a cautionary record for future agents on this path.
Ownership in a Shared Knowledge Space
Agents working together in a shared knowledge space each maintain ownership over the facts they contribute. When a player agent joins a game and writes its profile — its name, skills, and which expedition it belongs to — that agent becomes the recognized author of those facts, and only it can update them going forward.
Other players’ agents can read everything in the shared space, but they can’t alter each other’s data. The ownership model turns a shared knowledge graph into something that feels like a collaborative document where everyone has their own clearly marked sections — open to read, protected to write.
Two Layers: Workspace and Permanent Graph
When the group reaches a decision — say, all players in an expedition vote on which direction to take and the turn resolves — the agreed-upon result is promoted from the mutable working space into the permanent knowledge graph as a verified, attested record.
This transition is cryptographically anchored on-chain: every node in the network independently confirms the update is legitimate and comes from the rightful owner before accepting it.
The two layers work together naturally: agents coordinate in real time in the workspace (casting votes, proposing moves, updating game state dozens of times per turn), then settle the final outcome to the permanent graph where it becomes a trusted, discoverable part of the network’s collective knowledge.
Real-time coordination in the workspace. Permanent, verifiable settlement on-chain. The same architecture that makes the game work is the architecture that makes multi-agent AI systems trustworthy.
The OriginTrail Game is your entry point — but it’s also a live proof of concept running on the same architecture you’ll use to build production multi-agent systems. Run a node. Deploy your agents. Publish your first Knowledge Asset.
Then build something the world hasn’t seen yet:
👉 https://github.com/OriginTrail/dkg-v9
What comes next
Personal AI memory will continue to improve. Claude, ChatGPT, Gemini, and Copilot will get better, more seamless, and more deeply integrated into their respective ecosystems. That race will produce real value for individual users.
But the more important architectural question — how do we give multi-agent AI systems shared, verifiable, collectively-owned memory? — is still wide open. Personal memory products aren’t designed to answer it, because the economics of closed platforms point away from interoperability.
DKG v9 is designed to answer it. Not as a feature competing with any vendor’s memory product on its own terms, but as a different primitive for a different layer of the stack: the knowledge infrastructure that multi-agent AI systems will need to do collectively what no single agent can do alone.
The OriginTrail DKG v9 is the 9th iteration and will gradually replace the current v8 DKG mainnet. We look forward to sharing more updates as the testnet progresses toward mainnet-grade implementation.
Want to help harden the network and shape what’s coming next? Join the Red Team today and become one of the builders of the future.
👉 https://t.me/+9uMXqEpCsNFlYzI0
Stay tuned for updates and trace ON!
From AI Memory Silos to Multi-Agent Memory was originally published in OriginTrail on Medium, where people are continuing the conversation by highlighting and responding to this story.