
AI agents are getting very good at doing real work. Building a prototype is now almost effortless. You write a prompt, the system creates the structure, and you ship it. Agents can refactor code, connect APIs, generate user interfaces, run workflows, and even open pull requests while you’re still thinking about the next step.
But the big challenge in 2026 isn’t speed anymore. It’s trust.
When an agent runs day-to-day, you need to understand what it used, where the information came from, what changed over time, and why it made a decision.
Without that, teams run into the same problem again and again. The first demo looks amazing. Then reality hits. The agent forgets what happened last week, can’t explain where an answer came from, and starts mixing guesses with facts.
This is what some builders call agentic dementia.
And it becomes a serious issue the moment agents interact with systems such as transactions, production systems, identity, compliance, or reputation.
The trust gap
Today, most agents can’t reliably prove:
- What they used: the exact sources that informed the output
- Where it came from: who published the information and when
- What changed over time: versions you can trace and reproduce
- Why they acted: a decision trail you can inspect later
If your agent can’t show the trail behind an answer or action, you don’t have a trustworthy memory. You have a clever demo.
Why “RAG memory” hits a wall
A common setup for agent memory works like this: the system retrieves a few chunks from a vector database and adds them to the prompt.
This helps with recall, but it quickly breaks when you ask simple questions:
- Where did this information come from?
- Who authored it?
- Can I verify it independently?
- What changed, and when?
- Which sources did the agent rely on for this specific action?
- Can I audit this later without trusting a single database?
If you can’t reconstruct exactly what the agent used and why, the system becomes fragile and slowly drifts away from reality.
What trustworthy memory actually looks like
If you want agents that work beyond a one-time demo, you need something more than a collection of documents.
You need a shared context layer that persists across runs, tools, and even across multiple agents.
In practice, that context should be:
- Structured: build around entities and relationships, not just documents
- Queryable: so you can follow connections like project → decision → owner or policy → exception → approval
- Traceable: outputs link back to the inputs that shaped them
- Reusable: available across agents and workflows
- Verifiable: tamper-evident, with provenance you can validate
This is where OriginTrail Decentralized Knowledge Graph (DKG) comes in.
The DKG lets you store and use knowledge as a verifiable context graph, with provenance and traceability built in. Instead of relying solely on untraceable embeddings, agents can reference knowledge where sources are clear, relationships are preserved, and changes can be tracked over time.
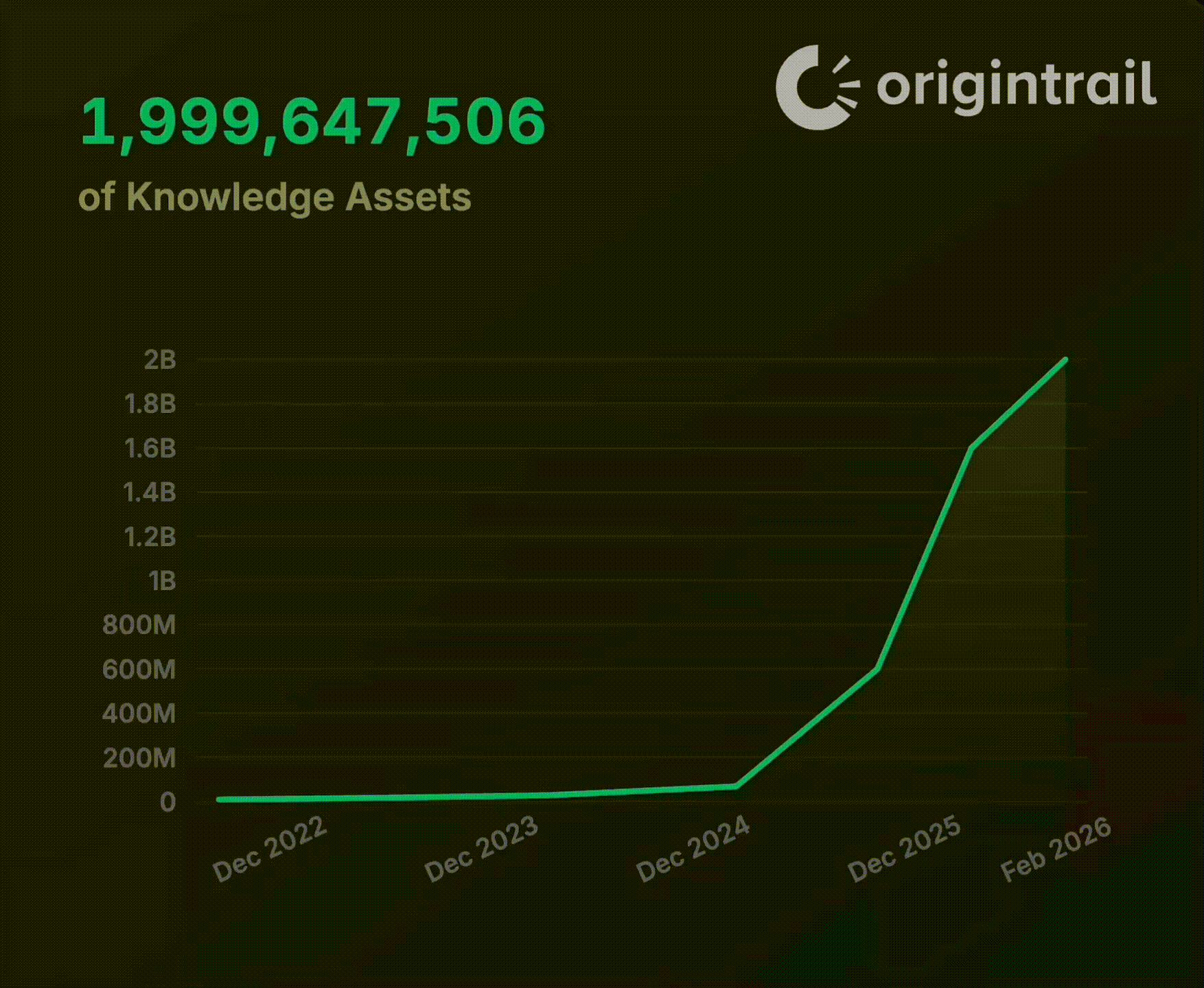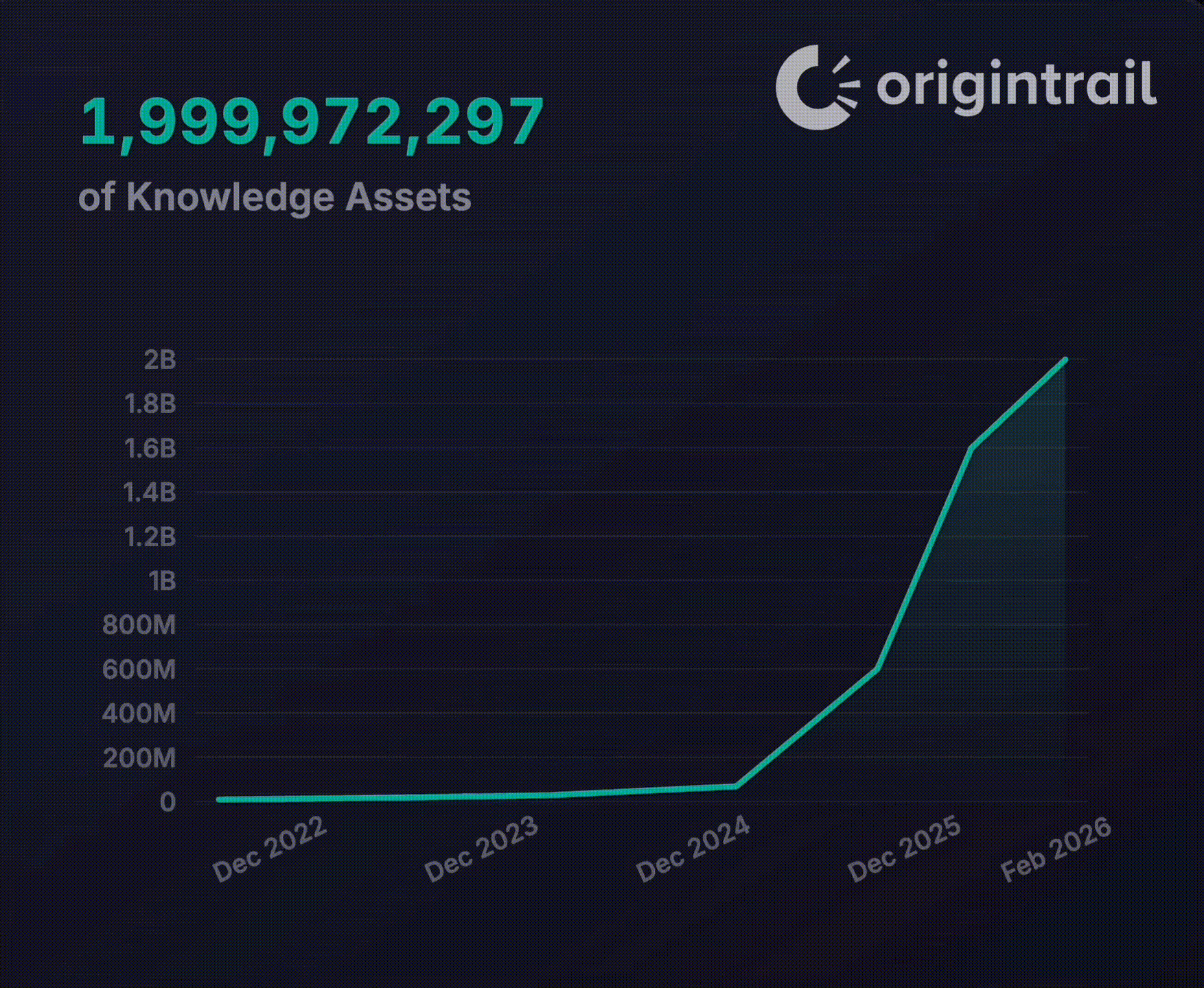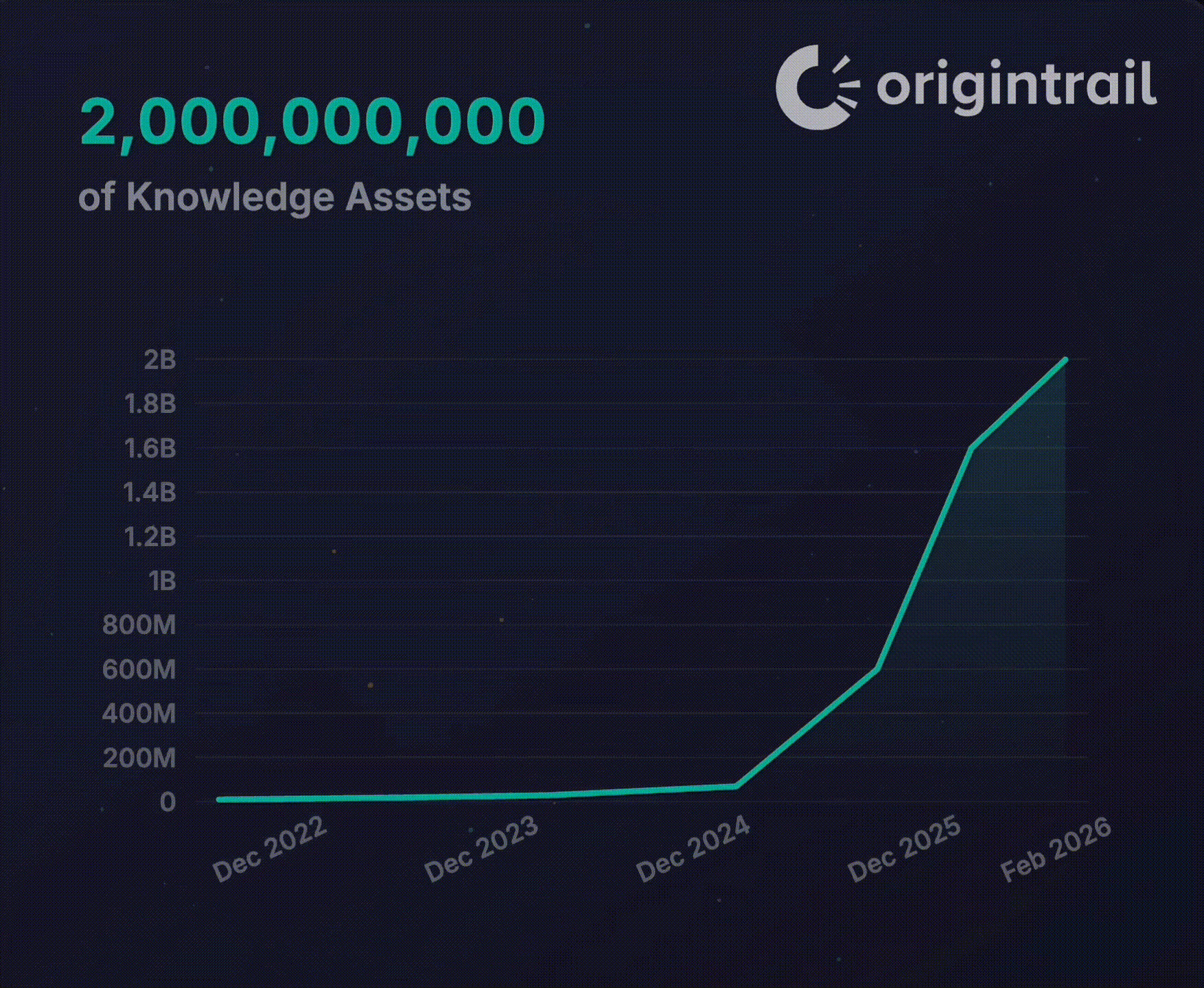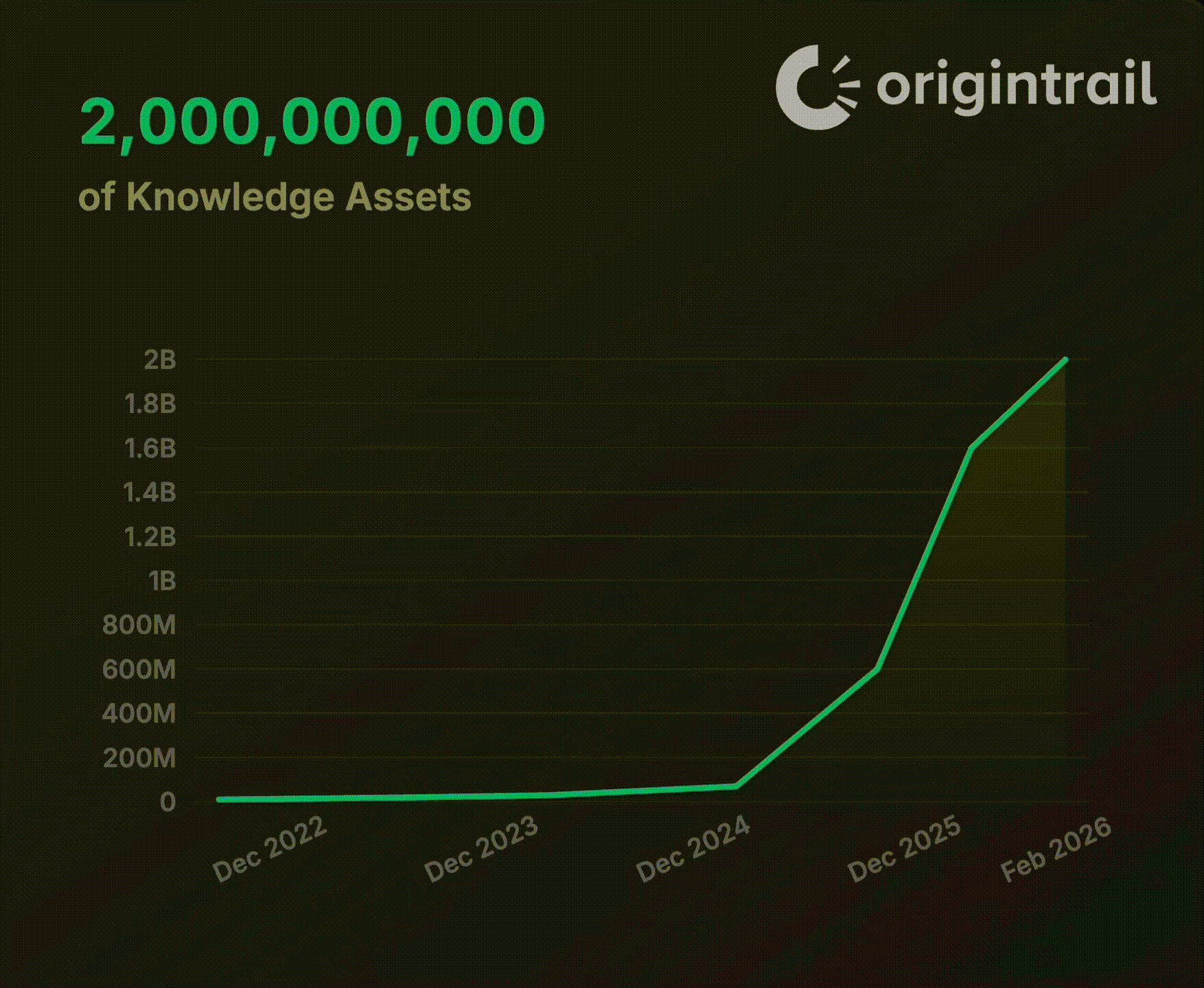
A practical pattern for verifiable agents
You don’t need a massive change to get started. Just treat memory as a core system component, not an afterthought. A practical approach could look like this:
- Publish critical context as Knowledge Assets
Store things like API contracts, schemas, policies, specs, vendor facts, approved actions, and known-good configurations as structured Knowledge Assets. These become dependable contexts for your agents. - Make retrieval auditable
Let agents query a context graph that contains entities, relationships, provenance, and versioning. This allows the agent to point directly to the knowledge it used. - Write outputs back with lineage
When an agent produces a decision, report, or change, publish it as a new Knowledge Asset that links back to the inputs it used. That turns outputs into traceable artifacts. - Verify before high-stakes actions
Before executing sensitive steps, verify the integrity and provenance of the assets the agent depends on. Keep the proof for later audit.
If you want a quick gut check, ask: “Can I see the trail behind this answer?”
If the answer is no, the system will not scale safely.
Trustworthy identity: agents need passports
Once memory and context become trustworthy, the next layer is identity.
AI agents are already managing wallets, executing trades, and interacting on your behalf, often with zero accountability infrastructure.
As agents become autonomous actors, they need a way to present:
- Who or what they are
- What they’re allowed to do
- What they’ve done, with an auditable history
- What they’re trusted for, based on validation and reputation
That’s why “agent passports” matter.
Standards like ERC-8004 are emerging for registries that provide identity, validation, and reputation for AI agents.

Dive deeper into the article: https://origintrail.io/blog/passport-please-ai-agents-are-becoming-first-class-citizens-with-erc-8004-origintrail-27fb90af8af9
Projects like ClawTrail, built on the OriginTrail Decentralized Knowledge Graph (DKG), are tackling this directly with a verifiable passport for every AI agent, a living TRAC(k) record (signed credentials, auditable history, certified capabilities), and agent-level KYC so you know who, or what, you’re dealing with.
Vibe coding made it easy to build and ship agents. Now everyone can ship agents that sound right.
The real advantage will belong to teams whose agents can prove where their knowledge came from, what changed, and why they made a decision.
Speed helps you ship demos. Verifiability helps you run real systems.
Start building AI agents with verifiable memory today — learn how in the OriginTrail official documentation.
The next wave of vibe coders won’t just ship agents. They’ll make them verifiable. was originally published in OriginTrail on Medium, where people are continuing the conversation by highlighting and responding to this story.